오늘의 목표는 크롤링 코드에 멀티프로세싱 적용하기!
기존 코드에 멀티프로세싱을 굳이 적용하는 이유는 AWS Lambda의 타임아웃 리밋이 15분이기 때문. 19000개의 네이버 지하철 시간표 홈페이지에 접속하고 정보를 크롤링, 특정 형식으로 자료를 정리해야 하기 때문에 15분은 굉장히 빠듯한 시간이다. 실제로 Lambda에서 900초 이후 Timeout 에러가 나면서 테스트 실패가 뜨는 현상이 있었음.

어떻게 하면 크롤링 코드를 더 개선할 수 있을까 고민해보았음.
첫번째 방법은 '100에서 20000까지 한 번에 돌리는 것이 아니라 100~10000 / 10001~20000까지 따로 돌려서 결과를 append한다'. 하지만 이것은 도메인? 특성상 하기 힘들었음. 어느 번호에 몇 호선의 어떤 역이 있는지 모르는 상태이고, 심지어 최종 결과물로는 호선 별로 정렬된 데이터가 나와야 하기 때문. 물론 아예 불가능하지는 않으나, 생각보다 꽤 큰 코드 구조 개선이 필요해 보였음. 따라서 기각.
두번째 방법은 멀티프로세싱. 마침 운영체제를 따로 공부하고 있었는데, 거기에서 아이디어를 얻었음. 이 작업은 페이지를 조회하고 그 페이지의 정보를 크롤링 하는 작업을 19000번 반복적으로 하는 작업. 즉, 프로세스 간 의존성이나 데이터의 의존성이 딱히 있지 않음. 병렬처리 하더라도 큰 문제가 없을 것 같아 멀티 프로세싱을 적용해보기로 함.
찾아보니 파이썬에는 Multiprocessing을 지원하고 있고, 크게 Process와 Pool로 그 방법이 나뉘는 것을 볼 수 있었음 (공식 문서 link)
처음에는 조금 더 명시적이고 직관적인 pool을 사용해서 코드를 작성
import requests
from bs4 import BeautifulSoup
import json
import time
from multiprocessing import Pool, cpu_count
def get_station_info(naver_code):
base_query = "https://pts.map.naver.com/end-subway/ends/web/{naver_code}/home".format(naver_code=naver_code)
page = requests.get(base_query)
soup = BeautifulSoup(page.text, "html.parser")
try:
line_num = soup.select_one('body > div.app > div > div > div > div.place_info_box > div > div.p19g2ytg > div > button > strong.line_no').get_text()
station_nm = soup.select_one('body > div.app > div > div > div > div.place_info_box > div > div.p19g2ytg > div > button > strong.place_name').get_text()
except:
return None
return {"station_nm": station_nm, "naver_code": naver_code, "line_num": line_num}
def find_code():
with Pool(6) as p:
codes = range(100, 20000)
results = p.map(get_station_info, codes)
INFO = {}
for result in results:
if result is None:
continue
line_num = result["line_num"]
station_nm = result["station_nm"]
naver_code = result["naver_code"]
if line_num not in INFO:
INFO[line_num] = []
print(station_nm)
block = {"station_nm": station_nm, "naver_code": naver_code}
INFO[line_num].append(block)
return INFO
if __name__ == "__main__":
start = time.time()
with open('subway_information.json', 'w', encoding='utf-8') as f:
json.dump(find_code(), f, ensure_ascii=False, indent=4)
end = time.time()
print(f"{end - start:.5f} sec")lambda가 최대 6개의 vCPU로 함수를 실행 가능하다고 해서 cpu 갯수는 6개로 설정했음.
로컬에서 돌려보니 어떨 때는 20분이 넘게 돌아가고, 어떨 때는 5분도 안 되어 다 돌아감.
첫번째 시도에서도 처음에는 잘 되다가 20% 넘기고 속도가 급격히 느려지는 지점이 있었음. 두번째는 그런게 없었음. 왜 속도가 일정하지 않은지는... 미스테리


안정적이지 않게 돌아가는 것을 보고 일차적으로 빡침. 하지만 우선 lambda에서 잘 돌아가주기만 한다면 나의 화는 줄어들었을 것임.
하지만 그럴리가.... lambda 친구는 OSError를 뱉으며 돌아가주지 않았음.
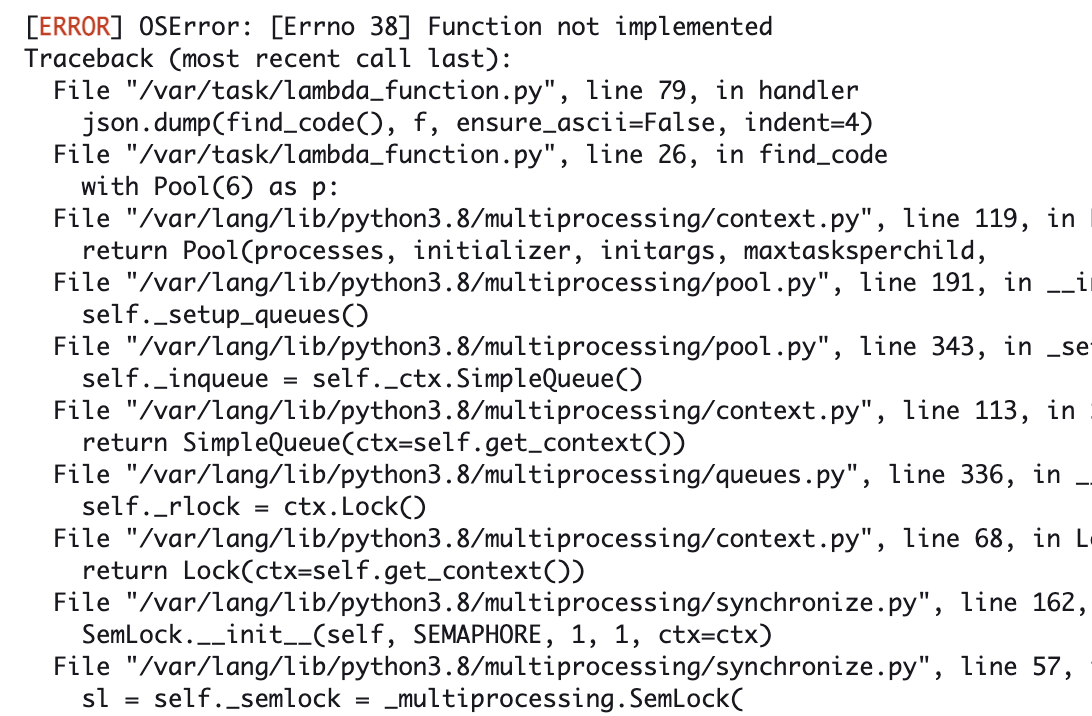
찾아보니 lambda에서는 Queue와 Pool을 지원해주지 않음 🤦
Due to the Lambda execution environment not having /dev/shm (shared memory for processes) support, you can’t use multiprocessing.Queue or multiprocessing.Pool.
공식문서를 보니 해당 내용이 있었고, pool 대신 Process와 Pipe를 이용한 방식을 사용하고 있었음.
하핳 ㅋㅋㅋㅋ 기껏 코드를 짰더니 지원 안 한다 허무...
내일 Process와 Pipe 적용한 코드로 다시 짜봐야지



