이전까지 "https://pts.map.naver.com/end-subway/ends/web/{역 코드}/home?timemode=" 에서 {역 코드}에 100~20000의 숫자를 입력, 해당 URL로 접속하여 지하철 정보가 없다면 패스, 있다면 호선 별로 역 코드와 역 이름을 스크래핑 해와 json 파일로 저장하는 Golang 코드를 설명하였다. (전체적인 코드는 아래 글에 https://kyumcoding.tistory.com/61 )
5. Go를 이용한 스크래퍼 리팩토링하기 (1) - Introduction, 그런데 goquery, S3 Upload, Lambda 활용 코드를 곁
이 글에서는 go에서 goquery, lambda, s3 다루는 법을 자세하게 설명하지는 않습니다. 이 블로그에 다른 글을 통해 업로드 할 예정입니다. 그래도 제가 사용한 소스 코드 전체는 있으니 참고 가능합니
kyumcoding.tistory.com
이번에 설명할 코드는 위 역 코드 스크래퍼에서 얻은 json 파일 내용을 입력으로 받아, 역 코드와 역 이름을 바탕으로 네이버 지하철 정보 페이지에 접속, 지하철 시간표를 스크래핑해오는 코드에 대해서 설명할 것이다.
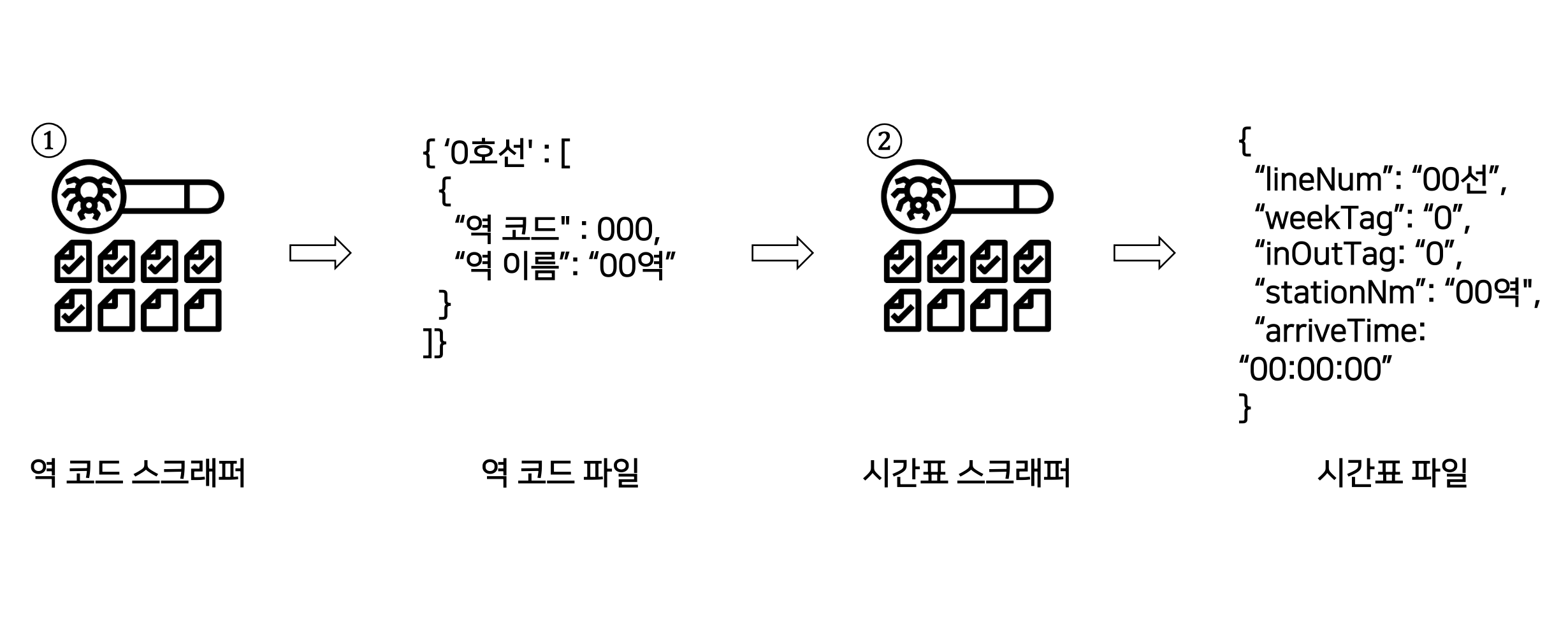
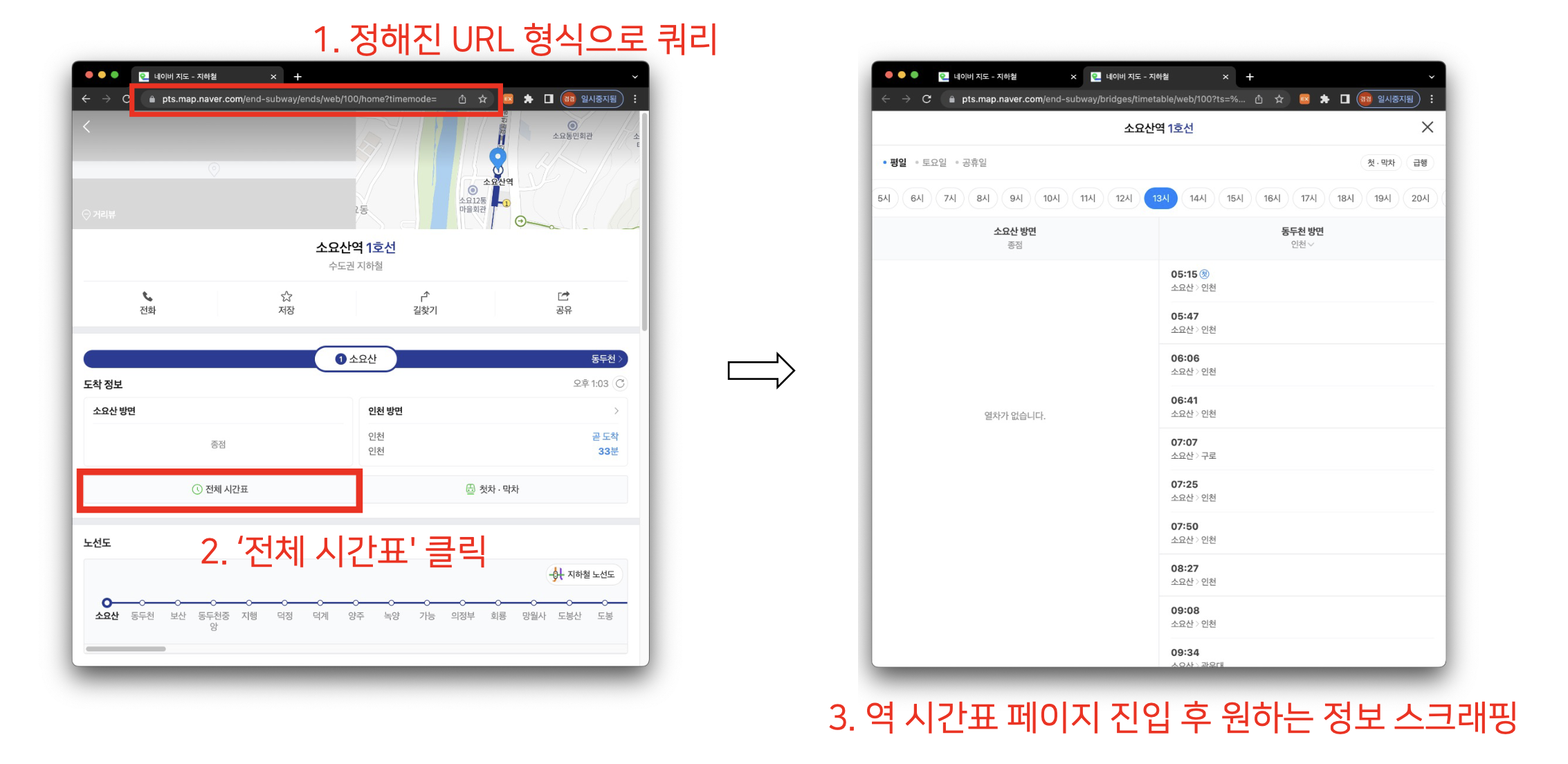
시간표를 얻는 과정(== 시간표 스크래퍼의 작동 과정)은 아래와 같다. 역 코드 스크래퍼로 생성한 역 코드 json 파일을 바탕으로 URL을 날려 네이버 웹페이지에 접근, '전체 시간표'를 클릭하여 역 시간표 페이지에 진입한다. 이후 해당 페이지에 표 형태로 나타나있는 지하철 도착 시간표를 스크래핑 해온다.
위 스크래퍼는 앞선 역 코드 스크래퍼와 마찬가지로 AWS Lambda 위에서 돌아가며, 도착 시간표 스크래핑 결과물은 Amazon S3에 업로드 한다. (역 코드 json 파일 역시 S3에서 다운로드 받는다) 코드 전체는 아래와 같다. (참고로 아래 스크래퍼 코드는 chromedp/headless-shell:113.0.5672.93 도커 이미지 위에서 돌아가기 때문에 main 함수 부분이 살짝 독특하다. 이 부분은 이후 포스트에서 다룰 예정)
- AWSConfigure 함수로 타 계정 S3 사용을 위한 credential을 설정하고 S3client를 생성한다
- S3Downloader로 S3에 업로드 되어 있는 subway_information.json 파일을 다운로드 받고, 해당 정보는 INFO 변수에 담는다
- for 문을 돌며 호선 별로 스크래핑을 한다 (+ 고루틴 사용)
- runCrawler에서는 각 호선 안에 역 코드와 역 이름을 각각 변수에 담고, 해당 변수를 바탕으로 타깃 페이지에 접속, 페이지 html 소스를 추출해와 필요한 정보를 변수에 담다 정리한다
- getHTMLContents 함수는 chromedp 라이브러리를 이용하여 타깃 페이지에 접속, outerHTML을 추출하는 역할
- crawler 함수는 획득한 outerHTML을 goquery 라이브러리를 이용하여 HTML에서 필요한 정보만 가져와 map 형식으로 정리한다
- makingFinalFileName 함수를 통해 각 호선 별로 정리된 시간표 데이터를 "년_월_일_timetable_호선이름.json" 이름 규칙으로 json 파일로 저장한다
- S3Uploader를 통해 각 호선 별로 정리된 시간표 데이터 json 파일을 S3에 업로드 한다
- runCrawler에서는 각 호선 안에 역 코드와 역 이름을 각각 변수에 담고, 해당 변수를 바탕으로 타깃 페이지에 접속, 페이지 html 소스를 추출해와 필요한 정보를 변수에 담다 정리한다
소스 코드 전체
package main
import (
"context"
"encoding/json"
"errors"
"fmt"
"github.com/PuerkitoBio/goquery"
"github.com/aws/aws-lambda-go/lambda"
"github.com/aws/aws-sdk-go-v2/aws"
"github.com/aws/aws-sdk-go-v2/config"
"github.com/aws/aws-sdk-go-v2/credentials"
"github.com/aws/aws-sdk-go-v2/service/s3"
"github.com/chromedp/cdproto/target"
"github.com/chromedp/chromedp"
"io"
"log"
"os"
"sort"
"strconv"
"strings"
"sync"
"time"
)
var (
subwayData map[string]string
data []map[string]string
mutex = new(sync.Mutex)
)
type BucketBasics struct {
S3Client *s3.Client
}
// 최종적으로 정보를 저장할 파일 이름(년_월_일_timetable_호선이름.json)을 만드는 함수
func makingFinalFileName(lineNum string) (string, string) {
loc, err := time.LoadLocation("Asia/Seoul")
checkErr(err)
now := time.Now()
t := now.In(loc)
fileTime := t.Format("2006_01_02")
finalFileName := fileTime + "_timetable_" + lineNum + ".json" // s3에 업로드 될 최종 파일 이름
return finalFileName, fileTime
}
// 에러 체킹용 함수
func checkErr(err error) {
if err != nil {
log.Fatalln(err)
}
}
// AWS S3 사용을 위한 credential 설정 & client 생성
func AWSConfigure() BucketBasics {
staticProvider := credentials.NewStaticCredentialsProvider(
os.Getenv("AWS_BUCKET_ACCESS_KEY"),
os.Getenv("AWS_BUCKET_SECRET_KEY"),
"")
sdkConfig, err := config.LoadDefaultConfig(
context.Background(),
config.WithCredentialsProvider(staticProvider),
config.WithRegion(os.Getenv("AWS_REGION")),
)
checkErr(err)
s3Client := s3.NewFromConfig(sdkConfig)
bucketBasics := BucketBasics{s3Client}
return bucketBasics
}
// struct를 json 형태로 변환 후 makingFileName에서 나온 이름으로 S3에 파일 업로드
func S3Uploader(data []map[string]string, basics BucketBasics, finalFileName string, fileTime string) error {
tmp, err := json.Marshal(data)
if err != nil {
log.Fatalf("JSON marshaling failed: %s", err)
}
// Elastic에 넣기 위해 데이터 형식 변경
justString := string(tmp)
content := strings.Replace(justString, "},{", "}\n{", -1)
content = strings.Trim(content, "[]")
// json 바이트 스트림을 S3에 업로드
_, err = basics.S3Client.PutObject(context.TODO(), &s3.PutObjectInput{
Bucket: aws.String(os.Getenv("AWS_BUCKET_NAME")),
Key: aws.String(fileTime + "/" + finalFileName),
Body: strings.NewReader(content),
})
if err != nil {
return fmt.Errorf("failed to upload, %v", err)
}
fmt.Println(finalFileName + "file successfully uploaded in S3")
return nil
}
// S3에서 파일 다운로드 후 json 데이터를 파싱하여 golang 자료 구조에 맞게 변환
func S3Downloader(basics BucketBasics) (map[string][]map[string]interface{}, error) {
result, err := basics.S3Client.GetObject(context.TODO(), &s3.GetObjectInput{
Bucket: aws.String(os.Getenv("AWS_BUCKET_NAME")),
Key: aws.String("subway_information.json"),
})
if err != nil {
log.Printf("Couldn't get object. Here's why: %v", err)
return nil, err
}
defer result.Body.Close()
body, err := io.ReadAll(result.Body)
if err != nil {
log.Printf("failed to read response body: %v", err)
return nil, err
}
var INFO = map[string][]map[string]interface{}{}
err = json.Unmarshal(body, &INFO)
checkErr(err)
return INFO, nil
}
// chromedp 설정 & 홈페이지 접속 후 시간표 탭 클릭하여 타겟 페이지 접속
func getHTMLContents(URL string) string {
// settings for crawling
opts := append(chromedp.DefaultExecAllocatorOptions[:],
chromedp.NoSandbox,
chromedp.Flag("disable-setuid-sandbox", true),
chromedp.Flag("disable-dev-shm-usage", true),
chromedp.Flag("single-process", true),
chromedp.Flag("no-zygote", true),
)
alloCtx, _ := chromedp.NewExecAllocator(context.Background(), opts...)
ctx, cancel := chromedp.NewContext(alloCtx, chromedp.WithLogf(log.Printf))
defer cancel()
var htmlContent string
ch := chromedp.WaitNewTarget(ctx, func(i *target.Info) bool {
return strings.Contains(i.URL, "/timetable/web/")
})
// 크롤링 대상 페이지에 접속하기 위해 URL 접속 -> 클릭
err := chromedp.Run(ctx,
chromedp.Navigate(URL),
// 클릭해야 할 부분이 나올때까지 기다리기
chromedp.WaitVisible(".end_footer_area"),
chromedp.Click("body > div.app > div > div > div > div.end_section.station_info_section > div.at_end.sofzqce > div > div.c10jv2ep.wrap_btn_schedule.schedule_time > button"),
)
checkErr(err)
// 클릭으로 새로운 탭이 생긴 곳으로 컨텍스트 옮기기 -> OuterHTML 추출
newContext, cancel := chromedp.NewContext(ctx, chromedp.WithTargetID(<-ch))
defer cancel()
if err := chromedp.Run(newContext,
chromedp.WaitReady(".table_schedule", chromedp.ByQuery),
chromedp.OuterHTML(".schedule_wrap", &htmlContent, chromedp.ByQuery),
); err != nil {
panic(err)
}
return htmlContent
}
// 타깃 페이지 HTML에서 필요한 정보만 추출 후 정리하기
func crawler(htmlContent string, lineNum string, stationNm string) {
doc, _ := goquery.NewDocumentFromReader(strings.NewReader(htmlContent))
// weektag 알아내기 & d에 기록
tag := doc.Find(".c1hj6oii.c92twem.btn_day.is_selected").Text()
switch tag {
case "평일":
tag = "1"
case "토요일":
tag = "2"
case "공휴일":
tag = "3"
}
// 시간표를 순회하며 inoutTag와 arriveTime 알아내기 -> 필요한 정보 가공 후 map 형태로 저장
doc.Find(".table_schedule > tbody > tr").Each(func(i int, tr *goquery.Selection) {
tr.Find("td").Each(func(j int, td *goquery.Selection) {
tmp := td.Find(".inner_timeline > .wrap_time > .time")
var arriveTime string
// 만약 빈 박스일 경우 무시 (for문 안이 아니라 continue는 못 씀)
if tmp.Text() == "" {
return
}
// arriveTime 정보 기록
arriveTime = tmp.Text() + ":00"
// inOutTag 정보 기록
var inOutTag string
switch j {
case 0:
inOutTag = "1" // 1: 상행
case 1:
inOutTag = "2" // 2: 하행
}
// 필요한 정보 모두 기록 & concurrent map writes 에러를 피하기 위한 mutex 설정
mutex.Lock()
subwayData = make(map[string]string)
subwayData["lineNum"] = lineNum
subwayData["stationNm"] = stationNm
subwayData["weekTag"] = tag
subwayData["arriveTime"] = arriveTime
subwayData["inOutTag"] = inOutTag
data = append(data, subwayData)
mutex.Unlock()
})
})
fmt.Println(lineNum, "호선 ", stationNm, " - 입력 완료")
}
// subway_information에서 각 호선의 네이버코드와 역이름 정보 가져오기 -> 해당 역이름 페이지로 접속하여 HTML 획득 -> crawler로 스크래핑
func runCrawler(val map[string]interface{}, baseURL string, lineNum string) {
// val안의 값들은 interface이기 때문에 type assertion 필요
naverCode := int(val["naverCode"].(float64)) // 왜인지 모르겠지만 처음 파일에서 interface로 값 가져올 때 float64로 가져와짐
stationNm := val["stationNm"].(string)
URL := baseURL + strconv.Itoa(naverCode) + "/home"
// 타깃 페이지에 접속하여 outerHMTL 획득
htmlContent := getHTMLContents(URL)
// 페이지 소스 크롤링 & 필요한 정보 정리하기
crawler(htmlContent, lineNum, stationNm)
}
func HandleRequest(_ context.Context) (string, error) {
start := time.Now()
bucktBasics := AWSConfigure()
INFO, err := S3Downloader(bucktBasics)
checkErr(err)
// INFO에서 key(호선 명) 뽑아내기
targetLines := make([]string, 0, len(INFO)) // capacity 설정 0을 안 넣어주면 오류 나옴;;
for k := range INFO {
targetLines = append(targetLines, k)
}
sort.Strings(targetLines)
// Lambda timeout으로 인해 일부만 크롤링: 1호선~5호선 (11분 41초) / 6호선~신림선 (14분 34초)
startLine, _ := strconv.Atoi(os.Getenv("START_LINE"))
endLine, _ := strconv.Atoi(os.Getenv("END_LINE"))
if startLine < 0 || endLine > len(targetLines) {
return "", errors.New("TARGET_LINES range Error")
}
targetLines = targetLines[startLine:endLine]
// 각 역의 정보를 바탕으로 크롤링 시작. for문을 돌며 호선 이름과 그 호선에 해당하는 역 정보 가져오고 -> 그거 바탕으로 크롤링
var baseURL string = "https://pts.map.naver.com/end-subway/ends/web/"
for _, lineNum := range targetLines {
info, _ := INFO[lineNum] // info: target 호선의 naverCode, stationNm으로 이루어진 slice
data = make([]map[string]string, 0, len(info)) // 각 호선의 데이터만 담을 수 있도록 슬라이스 초기화
fmt.Println("타겟 라인: ", lineNum, " 크롤링 시작")
// semaphore로 go 루틴 개수 15개로 제한, 각 go 루틴 실행 종료 시점 수집을 위한 채널 생성
sem := make(chan struct{}, 15)
done := make(chan struct{}, len(info))
for i, val := range info {
sem <- struct{}{} // semaphore를 획득하여 최대 go 루틴의 개수 제어
go func(val map[string]interface{}) {
runCrawler(val, baseURL, lineNum)
<-sem // go 루틴이 종료되면 semaphore를 반환
done <- struct{}{} // go 루틴이 종료되었음을 알리기 위해 done 채널에 값 전송
}(val)
if (i+1)%15 == 0 { // 네이버 서버에 부담을 주지 않도록 고루틴 15개마다 sleep
for j := 0; j < 15; j++ {
<-done
}
fmt.Println("--- 3초 휴식 ---")
time.Sleep(3 * time.Second)
}
}
// 모든 go 루틴이 종료될 때까지 done 채널에서 값 수신
for i := 0; i < len(info)%15; i++ {
<-done
}
// 정리한 정보를 json 파일 형식으로 저장 ("년_월_일_timetable_호선이름.json")
finalFilename, fileTime := makingFinalFileName(lineNum)
// 파일을 S3에 업로드
err := S3Uploader(data, bucktBasics, finalFilename, fileTime)
if err != nil {
fmt.Printf("S3Uploader failed, %v", err)
}
}
end := time.Since(start)
fmt.Println("총 실행시간 : ", end)
message := "NaverCrawler Successfully finished"
return message, nil
}
func main() {
if _, exists := os.LookupEnv("AWS_LAMBDA_RUNTIME_API"); exists {
lambda.Start(HandleRequest)
} else {
_, err := HandleRequest(context.Background())
if err != nil {
log.Fatal(err)
}
}
}
다음 포스트부터 본격적으로 코드의 파트 하나하나를 자세하게 설명하겠다. 앞선 포스트들에서 설명한 부분에 대해서는 달라진 부분만 설명하고 생략하여 최대한 빠르게 설명 진행할 예정이다.



