3.4 Interprocess Communication
두 개 이상의 프로세스가 동시에 실행되고 있을 때 독립적(independently)으로 실행될 때도 있지만, 서로 협력(cooperating)하여 실행되는 경우가 있음. 서로 협력한다는 것은 독립적인 프로세스 간 데이터를 주고받는다는 의미이며, 서로에게 영향을 주거나 받는 경우임. 이렇게 프로세스 간 통신하기 위해서는 IPC(Inter-Process Communication)매커니즘이 필요이라고 함.
IPC 매커니즘에는 크게 공유 메모리(Shared Memory) 모델과 메시지 패싱(Message Passing) 모델이 있음. 공유 메모리는 프로세스 간 데이터를 주고 받을 수 있는 별도의 메모리 공간을 생성하여 이용하는 방법, 메시지 패싱은 운영체제(커널)에게 데이터 주고받는 것을 맞기는 것(운영체제는 message queue를 활용하여 메시지 전달)

3.5 IPC in Shared-Memory Systems
공유 메모리 시스템을 이해하기 위해서 producer-consumer 모델을 생각하면 좋다.
- Producer
- 정보를 생산하여 buffer를 채운다
- 컴파일러가 어셈블리 코드를 생산, 웹서버가 HTML 파일을 생산
- 만약 buffer가 가득 찬다면 wait
- Consumer
- Producer가 생산하여 buffer에 넣은 것을 가져가 사용한다
- 어슴블러가 어셈블리 코드를 소비, 브라우저가 HTML 파일을 소비
- buffer가 빈 상황이라면 wait
위에서 등장하는 buffer를 shared memory로 구현하면 된다. 메모리의 한 영역 위에 구현되는 것이므로 OS가 관리하는 것이며, 각 프로세스의 외부에 만드는 것이기 때문에 프로세스의 메모리 프라이버시는 보장된다.
shared memory의 대략적인 구현
#define BUFFER_SIZE 10
typedef struct {
...
} item;
item buffer[BUFFER_SIZE];
int in = 0;
int out = 0;
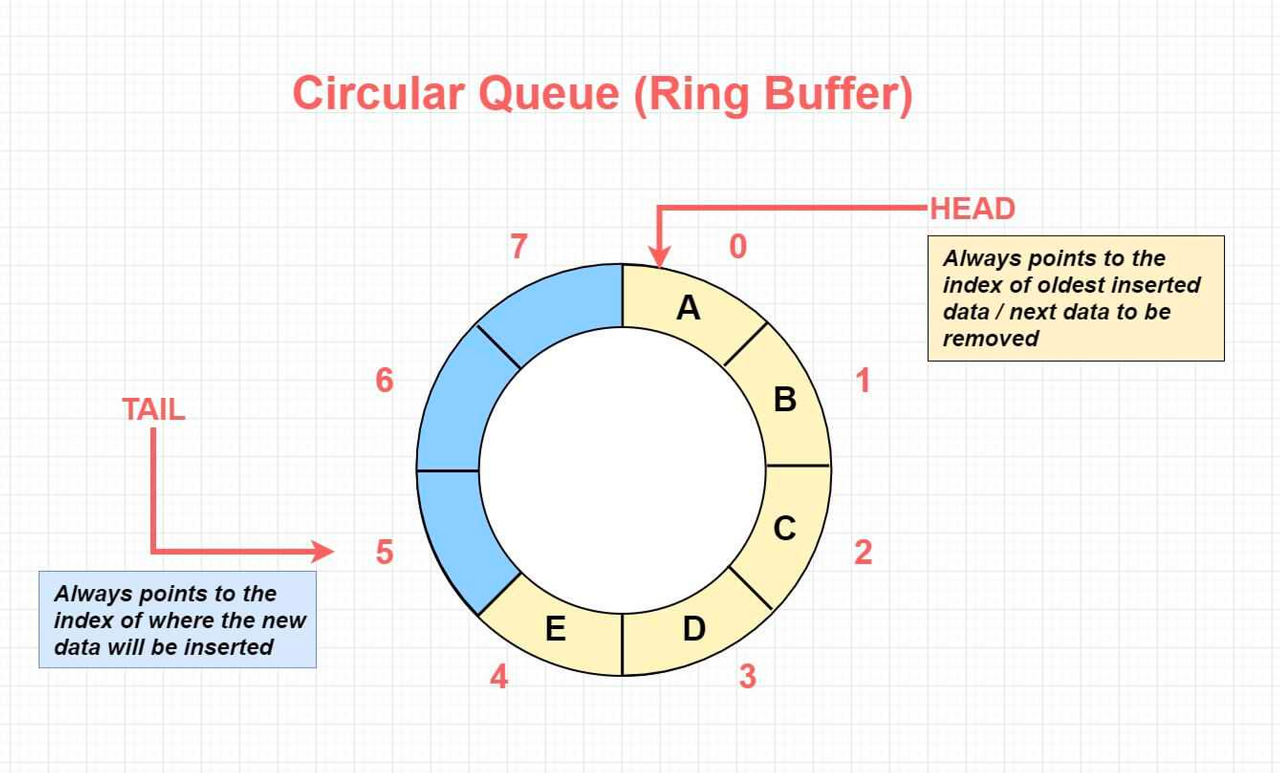
(buffer가 전역변수라 프로세스 내부에 있지만, 공유 메모리에 있다고 가정) 원형 큐(Circular Queue)로 만들어서 각 버퍼 영역에 정보가 들어가면 in이 증가하고, 컨슈머가 소비하면 out이 증가하고. in과 out이 같다면 empty 상태, in과 out이 버퍼 사이즈의 맨 마지막 다음에는 다시 0으로 돌아오고
item next_produced;
while (true) {
/* produce an item in next_produced */
while (((in + 1) % BUFFER_SIZE) == out)
; /* do nothing */
buffer[in] = next_produced;
in = (in + 1) % BUFFER_SIZE;
}
item을 만들어서 item buffer의 in 위치에 넣는다. in 보다 out이 1 큰 상황이라면 버퍼가 가득 찬 상황이므로 대기한다. 만약 버퍼에 빈 공간이 생기면 in을 1증가시키면서 in 안에 next_produced를 넣는다
item next_consumed;
while (true) {
while (in == out)
; /* do nothing */
next_consumed = buffer[out];
out = (out + 1) % BUFFER_SIZE;
/* consume the item in next_consumed */
}
in과 out이 같다는 것은 버퍼가 비어 소비할 것이 없다는 뜻이므로 대기한다. 소비할게 생긴다면 out을 1 증가시키고, out 안에 next_consumed를 가져온다
공유 메모리 시스템의 단점
메모리 영역을 조작하거나 접속하는 것을 개발자가 모두 관리해주어야 한다. 더욱이 producer와 consumer가 여러 개일 경우 문제는 더 복잡해짐. 이 단점이 message passing의 장점으로 이어짐 (OS가 알아서 다 관리해준다)
3.6 IPC in Message-Passing Systems
메시지 패싱은 개발자가 API만 쓰면 나머지는 OS가 다 알아서 해주는 접근을 취한다. 개발자는 메시지를 던지거나 받기만 하고, 나머지 처리(queue가 꽉차면 wait, 비어있으면 wait 등)는 OS가 관리해주는 방식이다. 아래 예시처럼 개발자는 send, recieve만 해주면 된다.
producer process using message passing
message next_produced;
while (true) {
/* produce an item in next_produced */
/* ex. next_produced=(item*)malloc(sizeof(item)) */
send(next_produced);
}
consumer process using message passing
message next_consumed;
while (true) {
recieve(next_consumed);
/* consume the item in next_consumed */
}
Communication Links
두 프로세스(P, Q) 간 메시지 패싱을 한다는 것은 프로세스 간 직접적으로 연결해주는 커뮤니케이션 링크를 만드는 것이라고 볼 수 있다(물론 중간에 OS가 처리해주는 많은 과정이 있지만). 프로세스 간 통신하기 위해서는 상호 간의 message send, recieve가 반드시 가능해야 한다. 이 커뮤니케이션 링크를 구현하는 몇 가지 유형이 있다.
- Direct / Indirect Communication
- Direct의 경우 sender와 recipient의 이름을 명확하게 적어주어야 한다 [send(P, message), receive(Q, message)]
- 이러한 경우 커뮤니케이션 링크가 자동(auotomatically establish)으로 생기며, 그 두 프로세스만 참여하는 딱 한 개의 링크가 생성된다(exactly one link, associated with excatly two processes)
- Indirect의 경우 프로세스 사이에 매개체(mailboxs, ports)를 두게 된다. port는 메시지를 적은 사람이 메시지를 넣고, 가져가는 사람이 메시지를 가져가는 하나의 오브젝트. Direct에서는 프로세스의 이름을 적었던 반면, indirect에서는 port의 이름을 적어서 메시지를 전송, 수신한다 [send(A, message), receive(A, message)]
- Indirect communication link는 오직 port가 있을 경우에만 성립이 가능. 2개 이상의 프로세스가 메시지를 넣고, 또 메시지를 가져갈 수 있다. 포트를 여러 개 두는 것도 가능하기 때문에 communication link가 2개 이상 존재할 수 있다.
- OS는 port를 create, delete하고, port에서 메시지를 send, recieve하는 기능만 사용자에게 지원해주면 된다.
- Direct의 경우 sender와 recipient의 이름을 명확하게 적어주어야 한다 [send(P, message), receive(Q, message)]
- Synchronous / Asynchronous Communication
- Blocking: 자신의 작업을 진행하다가 다른 작업이 시작되면 다른 작업이 끝날 때까지 기다렸다가 자신의 작업을 재실행 (제어권이 호출된 함수에게 있음)
- sender: sender가 메시지를 보내고 received될 때까지 block됨
- receiver: receive된 메시지가 available할 때까지 block됨
- Non-blocking: 자신의 작업을 실행하다가 다른 작업이 시작되어도 사진의 작업을 계속 실행 (제어권이 호출한 함수에게 있음)
- sender: sender가 메시지를 보내고 continue
- receiver: receiver가 vaild하거나 null인 메시지를 retrieve 하고 continue
- Syncronous, Asyncronous: 작업 도중 다른 작업을 호출하였을 때, 호출한 함수의 작업 완료 여부를 신경쓰는가 안 쓰는가
- Syncronous: 호출하는 함수가 계속 호출된 함수의 완료 여부를 물어보고, 보고 받는다
- Asyncronous: 호출하는 함수가 호출된 함수의 완료 여부를 신경 안 쓰고 있다가, 호출된 함수가 끝나서 callback을 전달받는다
- Blocking: 자신의 작업을 진행하다가 다른 작업이 시작되면 다른 작업이 끝날 때까지 기다렸다가 자신의 작업을 재실행 (제어권이 호출된 함수에게 있음)

- Automatic buffering / Explicit buffering
- Automatic buffering(unbounded): 무한한 길이의 buffer queue
- Explicit buffering(bounded): 유한한 길이의 buffer queue
3.7 Examples of IPC Systems
POSIX Shared Memory
공유 메모리 방식의 경우 POSIX(OS를 표준화하기 위한 단체)의 공유 메모리로 알아보겠음. POSIX의 공유 메모리의 경우 HDD가 아닌 메모리에 buffer를 잡아서(memory-mapped file)진행. 메모리에서 진행하기 때문에 훨씬 더 빠른 속도
1. shared-memory 오브젝트를 사용. shm_open에 이름(name)과 읽기쓰기 권한을 줘서 file description 생성 (file description - 유닉스 계열의 시스템에서 프로세스가 파일을 다룰 때 사용하는 개념으로, 프로세스에서 특정 파일에 접근할 때 사용하는 추상적인 값)
2. 위 file description 정보를 바탕으로 오브젝트의 크기를 ftruncate를 사용하여 지정
3. memory-mapped file에 mmap으로 fd를 매핑
fd = shm_open(name, O_CREAT | ORDWR, 0666);
// O_CREAT: 이름이 지정된 공유 메모리 객체가 이미 존재하지 않는 경우 새로운 객체를 생성
// O_RDWR: 공유 메모리 객체를 읽기 및 쓰기 모드로 열기
ftruncate(fd, 4096);
// 파일을 지정한 크기로 변경
mmap(0, SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
// PROT_READ: 매핑된 메모리 영역 읽기 가능
// PROT_WRITE: 매핑된 메모리 영역 쓰기 가능
// 0: 파일 또는 공유 메모리 객체 내에서 매핑의 시작 위치
하지만 shm_open해주고 읽고 닫아주고를 모두 개발자가 신경써서 진행해야 한다는 것이 단점
Pipe
유닉스 초창기에 사용하던 IPC 매커니즘. 두 프로세스의 커뮤니케이션을 위한 도구처럼 사용됨.
Pipe 구현에 있어서 4개의 고려 사항
1. Unidirectional vs Bidirectional
2. Half-duplex vs Full-duplex
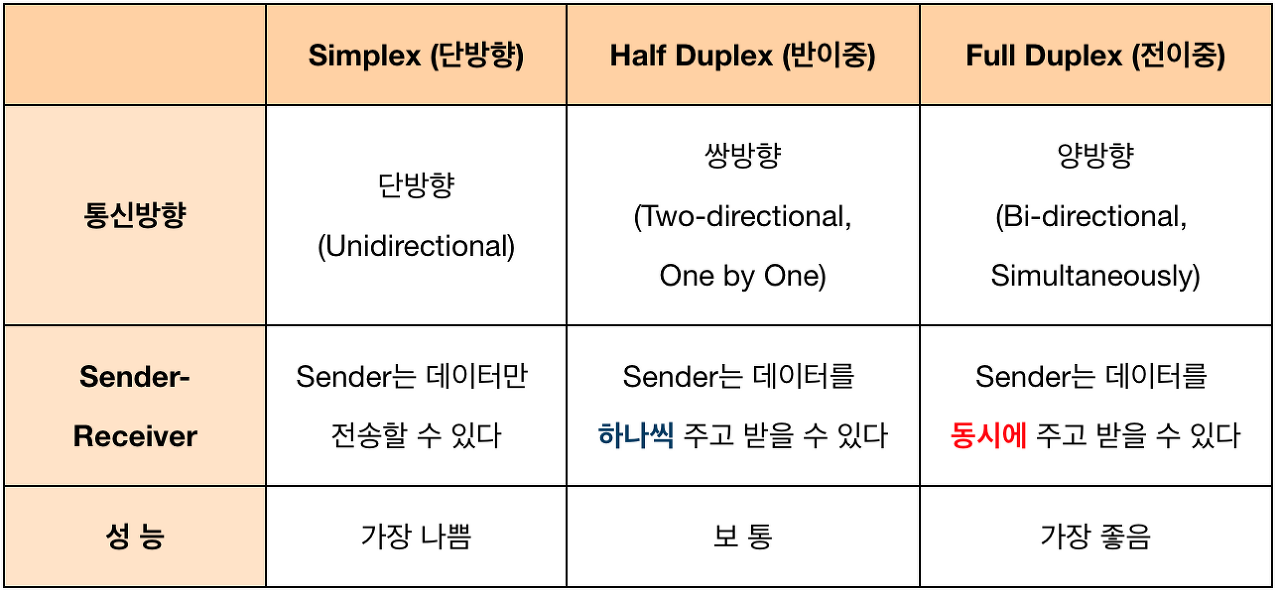
3. 커뮤니케이션 하는 프로세스 간의 관계 (ex. parent-child)
4. 네트워크를 통해서도 pipe로 통신 가능한지 (network를 사용할 수 있는 pipe를 socket이라고 함)
Pipe의 2가지 타입
- ordinary pipe: 2개의 프로세스가 parent-child 관계를 맺음. Parent가 pipe를 생성하고 child와 통신한다
- named pipe: 여러 개의 파이프를 생성하고 이름을 붙여줄 수 있다(parent-child relationship 아니어도 됨)
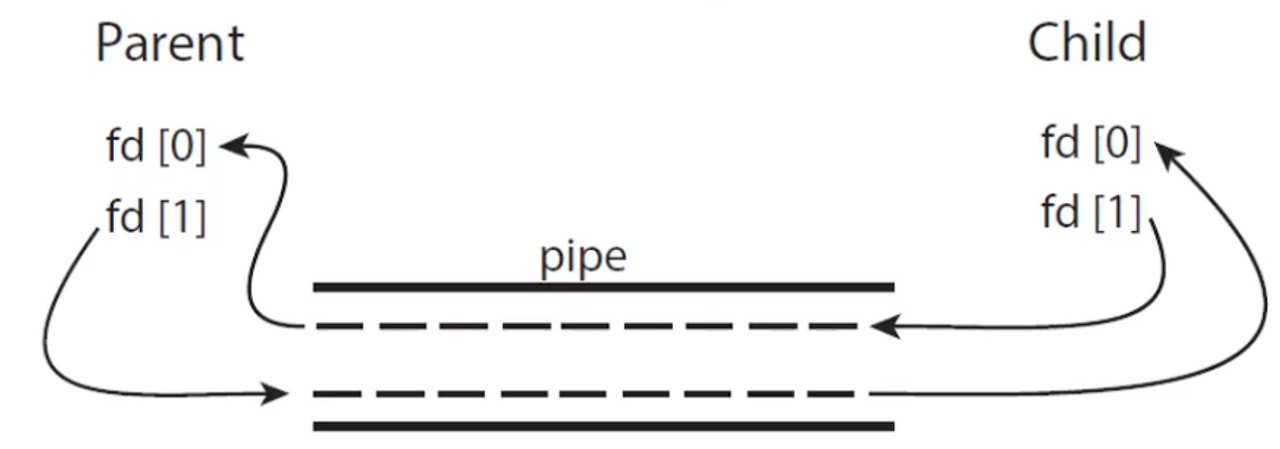
Ordinary pipe의 경우 양방향으로 통신하려면 one-way를 2개 만들면 된다. 하나는 프로듀서가 write하는데 사용하는 pipe (fd[1]), 다른 하나는 컨슈머가 read하는 pipe(fd[0]). 유닉스에서는 pipe 시스템 콜을 사용하여 구현할 수 있다.
아래 포스트에서 파이썬 코드로 pipe를 구현하여 사용하는 내용이 있으니 참고해봐도 좋을듯 하다
4. 파이썬 크롤링 코드에 Process, Pipe 적용하기
저번 시간에 AWS Lambda에서 Pool을 지원하지 않는다는 사실을 알게 되었다. (자세한 과정은 여기 참고) Process와 Pipe를 이용해서 코드를 다시 짜라는 말에 너무나 슬펐지만... 완성하려면 모... 짜야지
kyumcoding.tistory.com
3.8 Communication in Client-Server System
Socket
위에서 소개한 POSIX Shared memory나 pipe는 모두 깡통PC, 즉 인터넷이 연결되지 않았을 때 하나의 PC 안 프로세스끼리의 통신에 해당되는 이야기이다. 그렇다면 네트워크에 연결된 다른 컴퓨터에 있는 프로세스와의 통신은 어떻게 가능할까? 이때 바로 Socket이 등장한다.

Socket은 원격으로 연결된 두 엔드 포인트를 특정하고, 둘 사이에 통신을 가능하게 만든 것이다. 엔드 포인트를 특정하기 위해서는 2가지 정보가 필요한데, 하나는 IP Adress 다른 하나는 Port 번호이다. 이 둘을 합침으로써 네트워크 상에 있는 특정 컴퓨터의 프로세스를 찾을 수 있게 되었다. 다시 말하자면 socket은 원격의 두 프로세스가 통신하게 도와주는 일종의 pipe인데, ip address와 port를 바인딩한 것이라고 볼 수 있다.
| HTTP 통신 vs Socket 통신 HTTP 통신은 client의 요청이 있을 때만 server가 응답하는 단방향 통신. 클라이언트가 서버로부터 응답을 받으면 연결이 바로 종료된다(최근에는 Keep Alive 옵션 등으로 커넥션을 유지할 수 있긴 함) Socket 통신은 서버와 클라이언트가 특정 포트를 통해 실시간으로 양방향으로 통신하는 것. 서버 또한 클라이언트에게 요청을 보낼 수 있으며, 계속 연결을 유지하는 연결 지향형 통신이기 때문에 실시간 통신이 필요한 경우(ex. 스트리밍 서비스) 사용됨. HTTP 통신 또한 IP와 Port를 사용하는 등 Socket 통신의 일종이라고 볼 수 있음. 하지만 웹 통신에서 HTTP가 중요한 프로토콜로 여겨지기 때문에 둘을 구분하여 이야기 함. |
RPC (Remote Procedure Call)
RPC는 별도의 원격 제어 조작이 없어도 다른 주소 공간에서 함수나 프로시저(Procedure)를 실행할 수 있게 하는 IPC 기술이다. 일반적으로 프로세스는 자신의 주소공간 안에 존재하는 함수만 호출 가능한데, RPC를 사용할 경우 자신과 다른 주소공간에서 동작하는 프로세스의 함수를 실행할 수 있게 해준다. 최근 유행하는 MSA 구조의 경우 기능마다 다양한 언어와 프레임워크로 개발되는데, 이때 RPC를 사용하면 언어에 구애받지 않고 원격에 있는 프로시저를 호출할 수 있게 된다. RPC와 관련해서는 이후에 더 자세하게 다루는 것으로
| 함수 vs 프로시저 함수는 입력에 대한 결과 발생을 목적으로 함. 따라서 Return 값을 반드시 가져야 하고, 클라이어트단에서 처리되기 때문에 주로 간단한 계산 밒 수치 등을 도출할 때 사용한다. 반면 프로시저는 결과보다 '명령 단위가 수행하는 절차'에 집중한 개념. 따라서 Return 값이 없을 수도 있으며, 서버단에서 처리되기 때문에 함수보다 더 큰 단위의 실행, 프로세싱을 할 때 사용한다. |
'CS > 운영체제' 카테고리의 다른 글
| 운영체제 스터디 7주차 - Mutex, Semaphore, Monitor, Liveness (0) | 2024.01.31 |
|---|---|
| 운영체제 스터디 6주차 - 동기화 (1) | 2024.01.26 |
| 운영체제 스터디 5주차 - CPU 스케쥴링 (3) | 2024.01.24 |
| 운영체제 스터디 4주차 - 스레드 (1) | 2024.01.24 |
| 운영체제 스터디 2주차 - 프로세스의 이해 (0) | 2023.09.26 |



